The Visibility Problem, the Depth Buffer Algorithm and Depth Interpolation
Reading time: 21 mins.In the second chapter of this lesson devoted to the process of projecting points onto the screen, we learned that the third coordinate of the projected point (the point in screen space, which we refer to as \(V_{\text{proj}}\)) stores the original vertex's \(V\) z-coordinate (the z-coordinate of the point in camera space):
$$ \begin{array}{l} P_{\text{screen}}.x = \dfrac{ \text{near} \cdot P_{\text{camera}}.x }{ -P_{\text{camera}}.z}\\ P_{\text{screen}}.y = \dfrac{ \text{near} \cdot P_{\text{camera}}.y }{ -P_{\text{camera}}.z}\\ P_{\text{screen}}.z = -P_{\text{camera}}.z\\ \end{array} $$Finding the z-coordinate of a point on the surface of the triangle is useful when a pixel overlaps more than one triangle. The method to determine this z-coordinate involves interpolating the original vertices' z-coordinates using the barycentric coordinates we discussed in the previous chapter. In essence, we can treat the z-coordinates of the triangle vertices as any other vertex attribute and interpolate them in the same manner as we interpolated colors in the previous chapter. Before delving into the details of how this z-coordinate is computed, let's begin by explaining why it is necessary to do so.
The Depth-Buffer or Z-Buffer Algorithm and Hidden Surface Removal
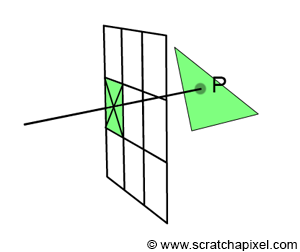
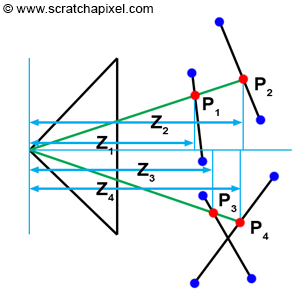
When a pixel overlaps a point, what we observe through that pixel is a small area on the surface of a triangle, which, for simplification, we will reduce to a single point (denoted as \(P\) in Figure 1). Thus, each pixel covering a triangle corresponds to a point on the surface of that triangle. Of course, if a pixel covers more than one triangle, we then have several of these points. The challenge arises when this happens, as we need to determine which one of these points is visible. This concept is illustrated in Figure 2.
One approach is to test triangles from back to front (this technique would require sorting triangles by decreasing depth first), but this doesn't always work when triangles intersect each other (see Figure 2, bottom). The only reliable solution is to compute the depth of each triangle that a pixel overlaps and then compare these depth values to find out which one is closest to the camera. In Figure 2, you can see that a pixel in the image overlaps two triangles at \(P1\) and \(P2\). However, the z-coordinate at \(P1\) (\(Z1\)) is lower than the z-coordinate at \(P2\) (\(Z2\)), so we can deduce that \(P1\) is in front of \(P2\).
This technique is necessary because triangles are tested in a "random" order. While we could sort triangles in decreasing depth order, this is not always sufficient. Generally, triangles are tested in the order they are specified in the program, which means a triangle (\(T1\)) closer to the camera can be tested before a triangle (\(T2\)) that is further away. Without comparing these triangles' depths, we might end up seeing the triangle that was tested last (\(T2\)), when in fact, we should be seeing \(T1\). This issue is known as the visibility problem or hidden surface problem. Algorithms that order objects so they are drawn correctly are called visible surface algorithms or hidden surface removal algorithms. The depth-buffer or z-buffer algorithm that we are going to study next belongs to this category of algorithms.
One solution to the visibility problem is to use a depth-buffer or z-buffer. A depth-buffer is nothing more than a two-dimensional array of floats that has the same dimensions as the frame-buffer and is used to store the depth of the object as the triangles are being rasterized. When this array is created, we initialize each pixel in the array with a very large number. If we find that a pixel overlaps the current triangle, we proceed as follows:
-
We first compute the z-coordinate or depth of the point on the triangle that the pixel overlaps.
-
We then compare that current triangle's depth with the value stored in the depth buffer for that pixel.
-
If we find that the value stored in the depth-buffer is greater than the depth of the point on the triangle, then the new point is closer to the observer or the camera than the point stored in the depth buffer at that pixel location. The value stored in the depth-buffer is then replaced with the new depth, and the frame-buffer is updated with the current triangle color. On the other hand, if the value stored in the depth-buffer is smaller than the current depth sample, then the triangle that the pixel overlaps is hidden by the object whose depth is currently stored in the depth-buffer.
Note that once all triangles have been processed, the depth buffer contains a type of image that represents the "distance" between the visible parts of the objects in the scene and the camera. This isn't an actual distance, but rather the z-coordinate of each point visible through the camera. The depth buffer is primarily useful for solving the visibility problem, but it can also be utilized in post-processing to implement effects such as 2D depth of field, adding fog, and shadow mapping—a method for casting shadows that doesn't rely on ray tracing. While these effects are generally more accurate when done in 3D, applying them in 2D is often faster, though not as precise (that's the tradeoff).
Here is an implementation of the depth-buffer algorithm in pseudo-code:
float *depthBuffer = new float[imageWidth * imageHeight];
// Initialize the depth-buffer with a very large number
for (uint32_t y = 0; y < imageHeight; ++y)
for (uint32_t x = 0; x < imageWidth; ++x)
depthBuffer[y * imageWidth + x] = INFINITY;
for (each triangle in the scene) {
// Project triangle vertices
...
// Compute the 2D triangle bounding-box
...
for (uint32_t y = bbox.min.y; y <= bbox.max.y; ++y) {
for (uint32_t x = bbox.min.x; x <= bbox.max.x; ++x) {
if (pixelOverlapsTriangle(x + 0.5, y + 0.5)) {
// Compute the z-coordinate of the point on the triangle surface
float z = computeDepth(...);
// The current point is closer than the object stored in the depth/frame-buffer
if (z < depthBuffer[y * imageWidth + x]) {
// Update the depth-buffer with that depth
depthBuffer[y * imageWidth + x] = z;
frameBuffer[y * imageWidth + x] = triangleColor;
}
}
}
}
}
Finding Z by Interpolation
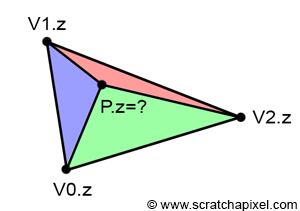

The principle of the depth buffer is straightforward and easy to understand. Now, let's explain how the depth values are calculated. To reiterate, the depth value represents the z-coordinate of a point on the triangle's surface that a pixel overlaps. When a pixel overlaps a triangle, it covers a small area on the triangle, which we simplify to a single point (point \(P\) in Figure 1). Our goal is to determine this point's z-coordinate. As mentioned earlier, if we know the z-coordinates of the triangle's vertices (which we do, as they are stored in the projected points), we can interpolate these coordinates using \(P\)'s barycentric coordinates (Figure 4):
$$P.z = \lambda_0 \cdot V0.z + \lambda_1 \cdot V1.z + \lambda_2 \cdot V2.z$$While this approach seems technically sound, it unfortunately doesn't work as expected. The issue isn't with the formula itself—it's perfectly valid. The problem arises after the triangle vertices are projected onto the canvas (following the perspective divide). At that point, the z-value we want to interpolate no longer varies linearly across the surface of the 2D triangle. This concept is easier to demonstrate with a 2D example.
Figure 4 will help illustrate where the problem lies and test the solution we will develop to fix it. Imagine we want to find the "image" of a line defined in 2D space by two vertices \(V0\) and \(V1\), with the canvas represented by the horizontal green line, located one unit away (along the z-axis) from the origin of the coordinate system. By tracing lines from \(V0\) and \(V1\) to the origin, we intersect the green line at two points (denoted as \(V0'\) and \(V1'\) in the figure), which lie on the canvas one unit away from the origin. The x-coordinates of these points can be calculated using perspective projection by dividing the original vertex x-coordinates by their respective z-coordinates:
$$ \begin{array}{l} V0'.x = \dfrac{V0.x}{V0.z} = \dfrac{-4}{2} = -2\\ V1'.x = \dfrac{V1.x}{V1.z} = \dfrac{2}{5} = 0.4 \end{array} $$Our task is to determine the z-coordinate of \(P\), a point on the line defined by \(V0\) and \(V1\), knowing only the position of its projection \(P'\) on the green line, with coordinates \(\{0,1\}\). As you may have already figured out, extended to the 3D case, \(P'\) would represent the pixel's center, and \(P\) is the point on the triangle that projects onto the pixel precisely at its center. But let's get back to our 2D example. We now compute the "barycentric coordinate" of \(P'\) with respect to \(V0'\) and \(V1'\), denoted as \(\lambda\). Like the barycentric coordinates for our triangle, \(\lambda\) falls within the range [0,1]. To find \(\lambda\), we measure the distance between \(V0'\) and \(P'\) (along the x-axis) and divide this by the distance between \(V0'\) and \(V1'\). If linear interpolation of the z-coordinates of the original vertices \(V0\) and \(V1\) using \(\lambda\) to find \(P\)'s depth works, we should obtain the value 4 (as visually deduced from the illustration, the coordinates of \(P\) are \(\{0,4\}\)). Let's first calculate \(\lambda\):
$$\lambda = \dfrac{P'x - V0'.x}{V1'.x - V0'.x} = \dfrac{0 - (-2)}{0.4 - (-2)}= \dfrac{2}{2.4} = 0.833$$Linearly interpolating the z-coordinates of \(V0\) and \(V1\) to determine \(P\)'s z-coordinate yields:
$$P.z = V0.z \cdot (1-\lambda) + V1.z \cdot \lambda = 2 \cdot (1 - 0.833) + 5 \cdot 0.833 = 4.5$$This is not the expected result (which is 4 remember?). Interpolating the original vertices' z-coordinates using \(P\)'s barycentric coordinates, or \(\lambda\) in this example, to find \(P\)'s z-coordinate is flawed. Why?
Simply put, perspective projection preserves lines but does not preserve distances. It is evident in Figure 4 that the ratio of the distance between \(V0\) and \(P\) over the distance between \(V0\) and \(V1\) (0.666) does not match the ratio of the distance between \(V0'\) and \(P'\) over the distance between \(V0'\) and \(V1'\) (0.833). If the \(\lambda\) value were 0.666, the interpolation would be accurate, but the problem lies in \(\lambda\) being 0.833. So, how do we accurately find \(P\)'s z-coordinate?
At this point, I'd like to emphasize that in computer graphics, we work with different types of transformations, each with specific properties. One type is the transformation used to move, rotate, or scale 3D objects in a scene. This is covered in the lesson on using matrices to control the size, rotation, and position of objects in a 3D scene. These transformations are called affine transformations. They preserve straight lines and, importantly, distances.
The second most important type of transformation in computer graphics is projection, which involves mapping 3D object space to 2D screen space. This type of mapping, often referred to as perspective projection mapping, preserves straight lines but does not preserve distances. It's crucial to understand these different types of mapping, and even more important to always remember the non-distance-preserving nature of perspective projection (unlike orthographic projections, which do preserve distances—check the lesson on orthographic and perspective projection matrices to learn more about these two projection types).
Keep this in mind as we will return to these concepts further in this chapter and the next one.
The solution is to calculate the inverse of \(P\)'s z-coordinate by interpolating the inverses of the z-coordinates of vertices \(V0\) and \(V1\) using \(\lambda\). Specifically:
$$\dfrac{1}{P.z} = \dfrac{1}{V0.z} \cdot (1-\lambda) + \dfrac{1}{V1.z} \cdot \lambda$$Let's check the result:
$$\dfrac{1}{P.z} = \dfrac{1}{2} \cdot (1 - \dfrac{2}{2.4}) + \dfrac{1}{5} \cdot (\dfrac{2}{2.4}) = 0.25$$Taking the inverse of this result gives us \(P\)'s z-coordinate value of 4, which is correct! As previously mentioned, the correct approach is to linearly interpolate the vertices' inverse z-coordinates using barycentric coordinates, and then invert the result to find \(P\)'s depth (its z-coordinate). For our triangle, the formula becomes:
$$\dfrac{1}{P.z} = \dfrac{1}{V0.z} \cdot \lambda_0 + \dfrac{1}{V1.z} \cdot \lambda_1 + \dfrac{1}{V2.z} \cdot \lambda_2$$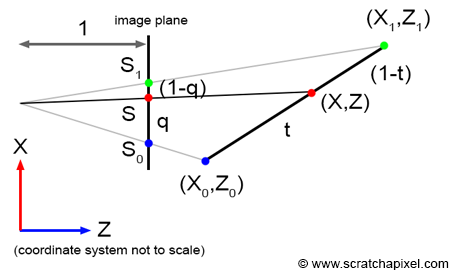
Let's examine this problem more formally. Why is it necessary to interpolate the inverse z-coordinates of the triangle vertices? The explanation is somewhat intricate, and you may choose to skip it. Consider a line in camera space defined by two vertices \(V_0\) and \(V_1\). The projection of these vertices onto the screen is denoted as \(S_0\) and \(S_1\), respectively. In this example, we assume the distance between the camera origin and the canvas is 1, as illustrated in Figure 5. Let \(S\) represent a point on the line defined by \(S_0\) and \(S_1\), resulting from the projection of point \(P\), a point on the line defined by \(V_0\) and \(V_1\). The parameters \(t\) and \(q\) are defined as follows:
$$ \begin{aligned} P &= V_0 \cdot (1-t) + V_1 \cdot t,\\ S &= S_0 \cdot (1-q) + S_1 \cdot q \end{aligned} $$This can also be expressed as:
$$ \begin{aligned} P &= V_0 + t \cdot (V_1 - V_0)\\ S &= S_0 + q \cdot (S_1 - S_0) \end{aligned} $$Thus, the \((x, z)\) coordinates of point \(P\) can be determined by interpolation (Equation 1):
$$ P_{x,z} = (V_0.x + t \cdot (V_1.x - V_0.x), V_0.z + t \cdot (V_1.z - V_0.z)) $$Similarly (Equation 2):
$$ S = S_0 + q \cdot (S_1 - S_0) $$\(S\)'s x-coordinate can also be calculated as:
$$ S.x = \dfrac{P.x}{P.z} $$This is a simple perspective divide, which you are now familiar with. Therefore:
$$ P.z = \dfrac{P.x}{S.x} $$Substituting the numerator with Equation 1 and the denominator with Equation 2 yields (Equation 3):
$$ P.z = \dfrac{V_0.x + t \cdot (V_1.x - V_0.x)}{S_0.x + q \cdot (S_1.x - S_0.x)} $$Also:
$$ \begin{aligned} S_0.x &= \dfrac{V_0.x}{V_0.z}\\ S_1.x &= \dfrac{V_1.x}{V_1.z} \end{aligned} $$Hence (Equation 4):
$$ \begin{aligned} V_0.x &= S_0.x \cdot V_0.z\\ V_1.x &= S_1.x \cdot V_1.z \end{aligned} $$Substituting \(V_0.x\) and \(V_1.x\) in Equation 3 with the expressions from Equation 4 gives (Equation 5):
$$ P.z = \dfrac{S_0.x \cdot V_0.z + t \cdot (S_1.x \cdot V_1.z - S_0.x \cdot V_0.z)}{S_0.x + q \cdot (S_1.x - S_0.x)} $$Recalling from Equation 1 (Equation 6):
$$ P.z = V_0.z + t \cdot (V_1.z - V_0.z) $$Combining Equations 5 and 6, we obtain:
$$ \begin{array}{l} (V_0.z + t \cdot (V_1.z - V_0.z)) \cdot (S_0.x + q \cdot (S_1.x - S_0.x)) = \\ S_0.x \cdot V_0.z + t \cdot (S_1.x \cdot V_1.z - S_0.x \cdot V_0.z) \end{array} $$Let's see how the equation can be simplified to express the parameter \(t\) in terms of \(q\). We proceed as follows:
1. Distribute and expand the terms on both sides:
$$ \begin{array}{l} V_0.z \cdot S_0.x + V_0.z \cdot q \cdot (S_1.x - S_0.x) + t \cdot (V_1.z - V_0.z) \cdot S_0.x \\ + t \cdot (V_1.z - V_0.z) \cdot q \cdot (S_1.x - S_0.x) = S_0.x \cdot V_0.z + t \cdot (S_1.x \cdot V_1.z - S_0.x \cdot V_0.z) \end{array} $$2. Isolate the term involving \(t\) to one side to solve for \(t\):
$$ \begin{array}{l} t \cdot [(V_1.z - V_0.z) \cdot S_0.x + (V_1.z - V_0.z) \cdot q \cdot (S_1.x - S_0.x) \\ - (S_1.x \cdot V_1.z - S_0.x \cdot V_0.z)] = -q \cdot V_0.z \cdot (S_1.x - S_0.x) \end{array} $$3. Further simplification yields:
$$ \begin{array}{l} t \cdot [V_1.z \cdot S_0.x - V_0.z \cdot S_0.x + (V_1.z - V_0.z) \cdot q \cdot (S_1.x - S_0.x) - S_1.x \cdot V_1.z + S_0.x \cdot V_0.z] = \\ -q \cdot V_0.z \cdot (S_1.x - S_0.x) \end{array} $$4. Factorizing to simplify the terms involving \(t\):
$$ t \cdot (S_1.x - S_0.x) \cdot [V_1.z - q \cdot (V_1.z - V_0.z)] = q \cdot V_0.z \cdot (S_1.x - S_0.x) $$5. Isolating \(t\), we obtain:
$$ t \cdot [q \cdot V_0.z + (1-q) \cdot V_1.z] = q \cdot V_0.z $$6. Simplifying to find \(t\) in terms of \(q\):
$$ t = \dfrac{q \cdot V_0.z}{q \cdot V_0.z + (1-q) \cdot V_1.z} $$This formulation demonstrates the relationship between the parameter \(t\), which is used to interpolate between two points in 3D space, and \(q\), which is used to interpolate between two points in 2D, on the screen.
Substituting for \(t\) in Equation 6 yields:
$$ \begin{array}{l} P.z &=& V_0.z + t \cdot (V_1.z - V_0.z) \\ &=& V_0.z + \dfrac{q \cdot V_0.z \cdot (V_1.z - V_0.z)}{q \cdot V_0.z + (1-q) \cdot V_1.z} \\ &=& \dfrac{V_0.z \cdot V_1.z}{q \cdot V_0.z + (1-q) \cdot V_1.z} \\ &=& \dfrac{1}{\dfrac{q}{V_1.z} + \dfrac{(1-q)}{V_0.z}} \\ &=& \dfrac{1}{\dfrac{1}{V_0.z} + q \cdot \left(\dfrac{1}{V_1.z} - \dfrac{1}{V_0.z}\right)} \end{array} $$Finally, we derive:
$$ \begin{array}{l} \dfrac{1}{P.z} &=& \dfrac{1}{V_0.z} + q \cdot \left(\dfrac{1}{V_1.z} - \dfrac{1}{V_0.z}\right) \\ &=& \dfrac{1}{V_0.z} \cdot (1-q) + \dfrac{1}{V_1.z} \cdot q \end{array} $$This formula concludes our formal exploration into why interpolating the inverse z-coordinates of the triangle vertices using the projected point's barycentric coordinates is the correct method for calculating the "unprojected" point \(P\)'s z-coordinate.
Remember when we discussed earlier in this chapter how projection from 3D object space into 2D screen space does not preserve distance? This is a characteristic of perspective projection and is the reason why simply interpolating the z-coordinates of the vertices using barycentric coordinates doesn't work.
The reason we highlight this concept is that you might encounter it referred to in older papers (as these topics are not as commonly discussed in modern papers) as rational-linear or hyperbolic interpolation. Both terms refer to the same concept. The idea is that, unlike standard linear interpolation, which simply interpolates between two values in a straight line, rational-linear interpolation considers the non-linear distortion introduced by perspective projection.
In perspective projection, depth and distance are perceived non-linearly. Objects further away from the camera appear disproportionately smaller than those closer to the camera. If you were to use simple linear interpolation for depth or any attribute affected by perspective, you would get incorrect results. This is why rational-linear or hyperbolic interpolation is used: it corrects for the perspective distortion by accounting for the non-linear nature of depth perception.
The expression \( \frac{1}{z_0} \cdot (1 - t) + \frac{1}{z_1} \cdot t \) is an example of rational-linear (or hyperbolic) interpolation used in perspective projection.
The quantity \( \frac{1}{z} \) is non-linear with respect to the depth \( z \). This non-linearity arises from the nature of perspective projection, where objects further away appear smaller at a rate that is not linear. Specifically, in a perspective projection, as an object moves further away from the camera, its screen size decreases in a manner proportional to \( \frac{1}{z} \), meaning the relationship between depth \( z \) and its representation in screen space is hyperbolic.
The reason we mentioned hyperbolas is that when you graph \( \frac{1}{z} \), you'll see that the curve approaches the x-axis (but never touches it) as \( z \) increases. Similarly, as \( z \) approaches 0, the curve shoots up towards infinity. This is characteristic of a hyperbola.
So, next time you see "Rational-Linear Interpolation" in a paper, you'll know what it means (and you'll definitely impress the people around you).

An alternative approach to explaining the depth interpolation issue involves considering the triangle (in 3D or camera space) lying on a plane. The plane equation is (Equation 1):
$$ AX + BY + CZ = D. $$Given that:
$$ \begin{aligned} X_{screen} &= \dfrac{X_{camera}}{Z_{camera}},\\ Y_{screen} &= \dfrac{Y_{camera}}{Z_{camera}}, \end{aligned} $$it follows that:
$$ \begin{aligned} X_{camera} &= X_{screen} \cdot Z_{camera},\\ Y_{camera} &= Y_{screen} \cdot Z_{camera}. \end{aligned} $$Substituting these into Equation 1 and solving for \(Z_{camera}\) yields:
$$ \begin{aligned} AX_{screen} \cdot Z_{camera} + BY_{screen} \cdot Z_{camera} + CZ_{camera} &= D,\\ Z_{camera} \cdot (AX_{screen} + BY_{screen} + C) = D,\\ \dfrac{D}{Z_{camera}} = AX_{screen} + BY_{screen} + C,\\ \dfrac{1}{Z_{camera}} = \dfrac{A}{D} \cdot X_{screen} + \dfrac{B}{D} \cdot Y_{screen} + \dfrac{C}{D},\\ \dfrac{1}{Z_{camera}} = A' \cdot X_{screen} + B' \cdot Y_{screen} + C', \end{aligned} $$where \(A' = \dfrac{A}{D}\), \(B' = \dfrac{B}{D}\), \(C' = \dfrac{C}{D}\).
This equation demonstrates that \(\dfrac{1}{Z_{camera}}\) is an affine function of \(X_{camera}\) and \(Y_{camera}\), which can be linearly interpolated across the surface of the projected triangle.
Z-Buffer Limitations and a Bit of History
The Z-buffer technique, which involves storing the depth of a point at each pixel in an image, is a simple and effective method for handling visibility in 3D scenes. However, it has some limitations, particularly when dealing with transparent surfaces. As mentioned before, one way to avoid using a Z-buffer is to sort triangles from the farthest to the nearest and process them in that order. However, this technique isn't entirely reliable, as triangles can intersect. In practice, GPUs utilize the Z-buffer technique, and transparent surfaces are often sorted from back to front. Still, there are situations, such as triangle intersections, where this can lead to incorrect results.
The Z-buffer was proposed by Ed Catmull in his 1974 paper, "A Subdivision Algorithm for Computer Display of Curved Surfaces" (yes, him again—if you haven't read the lesson on texturing yet, be sure to check it out).
An alternative method to the Z-buffer, mentioned here for reference, is the A-buffer (accumulation buffer). The idea behind the A-buffer is similar to that of the Z-buffer, but it allows for storing more than one point (or more precisely, to reuse the original paper's terms, more than one fragment) per pixel. If multiple transparent surfaces project onto the same pixel, the A-buffer stores all these points in a list (a list of fragments). Once all the triangles have been processed, these points (fragments) are composited together to determine the final color and opacity of the pixel. This technique is simple to implement, and we leave it to the reader to explore further.
As a trivia, the A-buffer method was described in Loren Carpenter's 1984 paper titled "The A-buffer, an Antialiased Hidden Surface Method." To our knowledge, this was the first instance where the term "fragment" was used. Today, this term is widely used in the GPU world to refer to the element in the graphics pipeline during the fragment shader stage, where the color of a pixel or pixel sample is calculated. In this context, a fragment refers to a structure that stores an 8x4 (8 columns, 4 rows) mask, where individual values are either 1 or 0, depending on whether the polygon (in our case, a triangle) covers the pixel at the sample location corresponding to that bit in the mask. This can be seen as a form of multi-sampling. All fragments contained in a pixel are then composited together, taking into account the mask of each fragment, its depth (the list is depth-sorted), its opacity, and its color, to produce the final opacity and RGB color for that pixel. Clever! This algorithm was the foundation of the REYES algorithm used by Pixar for its early movies.
Other Visible Surface Algorithms
As outlined in the introduction, the z-buffer algorithm is part of the broader category of hidden surface removal or visible surface determination algorithms. These algorithms are categorized into two groups: object space and image space algorithms. The "painter's algorithm", which has not been discussed in this lesson, falls under the object space category, whereas the z-buffer algorithm is classified as an image space algorithm. The painter's algorithm operates on the principle of rendering objects in a back-to-front sequence. This method necessitates the sorting of objects by depth. As mentioned earlier in this chapter, objects are initially processed by the renderer in an arbitrary sequence. Consequently, when two triangles intersect, determining which one is positioned in front of the other—and should therefore be rendered first—becomes challenging. Although the painter's algorithm is no longer in use, the z-buffer remains widely adopted, particularly in GPU implementations.