Expected Value of the Function of a Random Variable: Law of the Unconscious Statistician
Reading time: 7 mins.In this chapter, we will explain a concept that is very important for Monte Carlo methods. In the chapter on the expected value, we have explained how to compute the expected value of a discrete random variable X. The expected value of X is the sum of each outcome multiplied by its probability (given, as explained in the previous chapter, by the probability mass function or PMF). It can be seen as a weighted average:
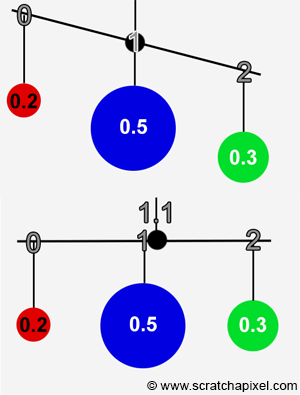
$$E[X] = \sum_{i=0}^{N-1} X_i pmf(X_i),$$where N denotes the number of possible outcomes that the random variable X can take on, and PMF is a probability mass function. It gives the probability of the outcome \(X_i\) to occur. As suggested in the previous chapters, computing this expected value is similar in a way to computing the center of mass of a mobile.
If we extend this concept to a continuous random variable, we get:
$$E[X] = \int_{-\infty}^{\infty} X pdf(X).$$This is an important result. Now, let's imagine that you have function f of x: f(x). Let's also imagine that this function is defined over a certain interval of x values. Let's note this interval [a,b]. We now imagine that the variable X is also defined in the interval [a,b]. In other words, each time you draw a number from X, you get some value in the interval [a,b]. The idea here is to use X as the parameter of the function f. In other words, f is a function of the random variable X which we can write as: f(X).
As a practical example, let's imagine we have a random variable X returning uniformly distributed integers in the interval 1 to 6. Uniformly distributed means that each one of these outcomes have a probability 1/6. Now let's imagine we have a function such as:
$$F(X) = (X - 3)^2.$$If we draw a random number from X, and it returns 2, then \(F(X) = (X - 3)^2\), with X = 2, which gives \(F(2) = (2 - 3)^2 = 1\).
What's important to note, is that if X is a random variable then F(X) is also a random variable. If we can't predict the outcome of X then we obviously can't predict the outcome of F(X). Both are random variables, however, note also that we can see F(X) as a function transforming X. In other words, F(X) is a transformed version of X. You should not assume that F(X) will have the same probability distribution function as X. In other words, the mapping or transform of X, leads to another probability distribution function. Keep in mind these two important ideas:
-
If X is a random variable, any function of X, F(X), will also be random.
-
X and F(X) have unique probability distribution (unless F(X) = X of course).
Note also that if we do know the probability distribution of X beforehand, if you wish to know the probability of F(X) you will need to calculate it (we will show how further down).
Let's get back to our example. So we know that in the case of a uniformly distributed random variable with possible outcome {1, 2, 3, 4, 5, 6}, the probability of each outcome is 1/6\. If the function F(X) is defined as \((X - 3)^2\), let's compute the probability distribution of F(X). For each outcome in X, we will need to compute the resulting outcome of F(X). Some of these outcomes will have the same value, thus increasing their probability. According to the multiplication rule, the probability of an outcome is equal to the number of times this outcome is in the set divided by the total possible number of outcomes (which is 6 in our experiment). Let's calculate:
$$ \begin{array}{l} X = 1, \; F(1) = (1-3)^2 = 4,\\ X = 2, \; F(2) = (2-3)^2 = 1,\\ X = 3,\;F(3) = (3-3)^2 = 0,\\ X = 4,\;F(4) = (4-3)^2 = 1,\\ X = 5,\;F(5) = (5-3)^2 = 4,\\ X = 6,\;F(6) = (6-3)^2 = 9. \end{array} $$As you can see in the table above, computing F(X) for each outcome in X, results in one zero, two ones, two fours, and one nine. The probability of an outcome Y from F(X) is equal to the sum of the probability of any of the X for which F(X) = Y. Thus we get:
$$ \begin{array}{l} Pr(F(0)) &=& \dfrac{1}{6}\\ Pr(F(1)) &=& \dfrac{1}{6} + \dfrac{1}{6} &=& \dfrac{2}{6}\\ Pr(F(4)) &=& \dfrac{1}{6} + \dfrac{1}{6} &=& \dfrac{2}{6}\\ Pr(F(9)) &=& \dfrac{1}{6}. \end{array} $$Now, if we wish to compute the expected value of F(X) we can proceed in two ways. If we know the probability distribution of F(X) we can write (method 1):
$$ \begin{split} E[F(X)]&=&0 \times Pr(F(X) = 0) + 1 \times Pr(F(X) = 1) +\\ &&4 \times Pr(F(X) = 4) + 9 \times Pr(F(X) = 9),\\ &=&0 * \dfrac{1}{6} + 1 * \dfrac{2}{6} + 4 * \dfrac{2}{6} + 9 * \dfrac {1}{6},\\ &=&3.167. \end{split} $$Mathematically, if we call Y the random variable F(X) and \(P_Y\), the probability distribution of Y, we get:
$$E[F(X)] = E[Y] = \sum Y_i P_Y(Y_i).$$Where the sum is over all possible values of Y (in our example 4: {0,1,4,9}).
Or if you don't know the probability distribution of F(X), you can still use your knowledge of the probability distribution of X to calculate E[Y] (method 2):
$$ \begin{split} E[F(X)] & = &(1-3)^2\times Pr(X = 1) + (2-3)^2\times Pr(X = 2) +\\ && (3-3)^2\times Pr(X = 3)+ (4-3)^2\times Pr(X = 4) +\\ && (5-3)^2\times Pr(X = 5) + (6-3)^2\times Pr(X = 6)\\ &=&4 * \dfrac{1}{6} + 1 * \dfrac{1}{6} + 0 * \dfrac{1}{6} + 1 * \dfrac{1}{6} + 4 * \dfrac{1}{6} + 4 * \dfrac{1}{6}\\ &=&3.167. \end{split} $$Mathematically we would write this result as:
$$E[F(X)] = F[Y] = \sum F(X_i) P_X(X_i).$$Where the sum is over all possible values of X (in our example 6: {0,1,2,3,4,5,6}).
This is an important result because, in practice, you don't necessarily know the probability distribution of F(X). Of course, you can calculate it, but this is an extra step, which you can avoid if you use the second method. Mathematically, this result can be written as:
for a discrete random variable, and:
$$E[F(X)] = \int F(X) P_X(X) \:dX,$$for continuous random variables. These equations are very important and play an essential role in Monte Carlo methods. In mathematics, they are sometimes referred to as the law of the unconscious statistician. We are not too sure why, but the common explanation is that in fact, most people don't realize that when they compute something such as the expected value of the function of a random variable, rather than using the first solution to compute E[F(X)] (where we use the probability distribution of F(X)), we use the second solution (where we use the probability distribution of X):
When the statistician thinks he/she computes: \(E[Y] = \sum Y_i P_Y(Y_i)\), what he/she often computes is actually \(E[F(X)] = \sum X_i P_X(Y_i)\). While the result is the same, one requires the probability distribution of F(X) when the second doesn't.
Keep in mind that the beauty of the method is that it is not necessary to know the probability distribution of F(X) to compute its expected value, as long as you know the probability distribution of X.
This result is the foundation of Monte Carlo integration.