A Quick Introduction to Monte Carlo Methods
Reading time: 23 mins.Originally we didn't want the lesson to be so long and to contain so much information about probability and statistics, but the reality is, if you want to understand Monte Carlo methods, you need to cover a lot of ground in probability and statistics theory.
In this chapter, we will try to give a sense of what these Monte Carlo methods are, how they work, why, and what they are used for. This quick introduction is for readers who do not have the time or the desire to get any further. But you may need to read all the remaining chapters if you are serious about learning what these methods are.
This lesson is more of an introduction to the mathematical tools upon which the Monte Carlo methods are built. The methods themselves are explained in the next lesson (Monte Carlo Methods in Practice).
A Foreword about Monte Carlo
Like many other terms which you can frequently spot in CG literature, Monte Carlo appears to many non-initiated as a magic word. And unlike some mathematical tools used in computer graphics such as spherical harmonics, which to some degrees are complex (at least compared to Monte Carlo approximation) the principle of the Monte Carlo method is on its own relatively simple (not to say easy). This is great because this method is extremely handy to solve a wide range of complex problems. Monte Carlo integration or approximation (the two terms can be used however integration is generally better) is probably an old method (the first documented reference to the method can be found in some publications by mathematician Comte de Buffon in the early 18th century) but was only given its current catchy name sometime in the mid-1940s. Monte Carlo is the name of a district in the principality of Monaco famous for its casinos. As we will explain in this lesson, the Monte Carlo method has a lot to do with the field of statistics which on its own is very useful to appreciate your chances to win or lose at a game of chance, such as roulette, anything that involves throwing dice, drawing cards, etc., which can all be seen as random processes. The name is thus quite appropriate as it captures the flavor of what the method does. The method itself, which some famous mathematicians helped to develop and formalize (Fermi, Ulam, von Neumann, Metropolis, and others) was critical in the research carried on in developing the atomic bomb (it was used to study the probabilistic behavior of neutron transport in fissile materials) and its popularity in modern science has a lot to do with computers (von Neumann himself built some of the first computers). Without the use of a computer, Monte Carlo integration is tedious as it requires tons of calculations, which computers are very good at. Now that we have reviewed some history and given some information about the origin of the method's name, let's explain what Monte Carlo is. Unfortunately though as briefly mentioned before, the mathematical meaning of the Monte Carlo method is based on many important concepts from statistics and probability theory. We will first have to review these concepts (and introduce them to you) before looking at the Monte Carlo method itself.

A Quick Introduction to Monte Carlo Methods

What is Monte Carlo? The concept behind MC methods is both simple and robust. However as we will see very soon, it requires a potentially massive amount of computation, which is the reason its rise in popularity coincides with the advent of computing technology. Many things in life are too hard to evaluate exactly especially when it involves very large numbers. For example, while not impossible, it could take a very long time to count the number of Jelly beans that a 1 Kg jar may contain. You might count them by hand, one by one, but this might take a very long time (as well as not being the most gratifying job ever). Calculating the average height of the adult population of a country would require measuring the height of each person making up that population, summing up the numbers, and dividing them by the total number of people measured. Again, this a task that might take a very long time. What we can do instead is take a sample of that population and compute its average height. It is unlikely to give you the exact average height of the entire population, however, this technique gives a result that is generally a good approximation of what that number is. We traded off accuracy for speed. Polls are also known as statistics are based on this principle which we are all intuitively familiar with. Funnily enough, the approximation and the exact average of the entire population might sometimes be the same. This is only due to chance. In most cases, the numbers will be different. One question we might want to ask though, is how different? In fact, as the size of the sample increases, this approximation converges to the exact number. In other words, the error between the approximation and the actual result is getting smaller as the sample size increases. Intuitively, this idea is easy to grasp, however, we will see in the next chapter, that it should be (from a mathematical point of view) formulated or interpreted differently. Note that to be fair, elements making the sample need to be chosen randomly with equal probability.
Note that the height of a person is a random number. It can be anything really which is the nature of random things. Thus, when you sample a population, by randomly picking up elements of that population and measuring their height to approximate the average height, each measure is a random number (since each person from your sample is likely to have a different height). Interestingly enough, a sum of random numbers is another random number. If you can't predict what the number making up the sum are, how can you predict the result of their sum? So, the result of the sum is a random number, and the numbers making up the sum are random.
For a mathematician, the height of a population would be called a random variable, because the height among people making up this population varies randomly. We generally denote random variables with upper case letters. The letter X is commonly used.
In statistics, the elements making up that population, which as suggested before are random, are denoted with a lower capital letter, generally \(x\) as well. For example, if we write \(x_2\), this would denote the height (which is random) of the second person in the collection of samples. All these \(x\)'s can also be seen as the possible outcomes of the random variable X. If we call X this random variable (the population height), we can express the concept of approximating the average adult population height from a sample with the following pseudo-mathematical formula:
$$Approximation(Average(X)) = { 1 \over N} \sum_{n=1}^N x_n.$$Which you can read as, the approximation of the average value of the random variable X, (the height of the adult population of a given country), is equal to the sum (the \(\Sigma\) sign) of the height of N adults randomly chosen from that population (the samples), divided by the number N (the sample size). This, in essence, is what we call a Monte Carlo approximation. It consists of approximating some property of a very large number of things, by averaging the value of that property for N of these things chosen randomly among all the others. You can also say that Monte Carlo approximation, is a method for approximating things using samples. What we will learn in the next chapters, is that the things which need approximating are called in mathematics expectations (more on this soon). As mentioned before the height of the adult population of a given country can be seen as a random variable X. However, note that its average value (which you get by averaging all the heights for example of each person making up the population, where each one of these numbers is also a random number) is unique (to avoid confusion with the sample size which is usually denoted with the letter N, we will use M to denote the size of the entire population):
$$Average(X) = { 1 \over M\ } (x_1 + x_2 + ... x_M),$$where the \(x_1, x_2, ... x_M\) corresponds to the height of each person making up the entire population as suggested before (if we were to take an example). In statistics, the average of the random variable X is called an expectation and is written E(X).
To summarize, Monte Carlo approximation (which is one of the MC methods) is a technique to approximate the expectation of random variables, using samples. It can be defined mathematically with the following formula:
$$E(X) \approx { 1 \over N } \sum_{n = 1}^N x_n.$$The mathematical sign \(\approx\) means that the formula on the right inside of this sign only gives an "approximation" of what the random variable X expectation E(X) is. Note that in a way, it's nothing else than an average of random values (the \(x_n\)s).
If you are just interested in understanding what's hiding behind this mysterious term Monte Carlo, then this is all you may want to know about it. However for this quick introduction to be complete, let's explain why this method is useful. It happens as suggested before that computing E(X) is sometimes intractable. This means that you can't compute E(X) exactly at least not in an efficient way. This is particularly true when very large "populations" are concerned in the computation of E(X) such as with the case of computing the average height of the adult population of a country. MC approximation offers in this case a very simple and quick way to at least approximate this expectation. It won't give you the exact value, but it might be close enough at a fraction of the cost of what it might take to compute E(X) exactly, if or possible at all.
Monte Carlo, Biased and Unbiased Ray Tracing
To conclude this quick introduction, we realize that many of you have heard the term Monte Carlo ray tracing as well as the term biased and unbiased ray tracing and probably looked at this page, hoping to find an explanation to what these terms mean. Let's quickly do it, even though we do recommend that you read the rest of this lesson as well as the following ones, to get in-depth answers to these questions.

Imagine you want to take a picture with a digital camera. If you divide the surface of your images into a regular grid (our pixels), note that each pixel can be seen as a small but continuous surface on which light reflected by objects in the scene falls. This light will eventually get converted to a single color (and we will talk about this process in a moment) however if you look through any of these pixels, you might notice that it sees more than one object, or that the color of the surface of the object that it sees, varies across the pixel's area. We have illustrated this idea in Figure 1. What we want to do, ideally, is to compute the amount of light reflected from this surface across the pixel area. This is typical of an intractable problem, in the sense that there is no method by which you can integrate over the surface of a pixel, the amount of light passing through that pixel. While we can write this idea mathematically, there is no solution to this equation as such:
$$L_{pixel} = \int_{pixel area} L(x_p) dA,$$where L here, stands for radiance (as explained in the lesson on radiometry). You can read this equation as "the amount arriving on a pixel (the L term on the left side of the equation which is also the color that will eventually be saved for that pixel) can be computed as the integral of the incoming radiance (light striking the pixel) over the pixel area". As we just said, there is no analytical solution to this problem thus we need to use a numerical approximation instead.

Again the principle here is very simple. It consists of approximating the result of this integral, by sampling the surface of the pixel at several locations across the pixel area. In other words, as with the case of the Monte Carlo approximation, we will use "random sampling" to evaluate this integral (and get an approximation for it). All we need is to select a few random sample locations across the pixel area and average their color. The problem now is how do we find the color of these samples. Using ray tracing of course! Rays will start at the eye position as usual but will pass through each randomly placed sample laid out across the area of the pixel (Figure 2). The color of the samples will be the color of the rays at their intersection point with the objects from the scene. Mathematically, we can write:
$$L_{pixel} \approx {1 \over N } \sum_{n=1}^N L(x_n),$$where \(L(x_n)\) denotes the sample color. As usual, this is only an approximation (hence the \(\approx\) sign). This method is called a Monte Carlo integration (even though similar to the Monte Carlo approximation method, it is used in this case to find an approximation to an integral). You will find a formal definition of the Monte Carlo integration method in the next lesson. This is just an informal and quick introduction to the concept.
If you don't yet understand the problem well, let's just imagine that the surface of the pixel we are looking through is covered by a 16x16 grid of colors (as in depicted in Figure 3). The problem might seem simpler because we only have 256 distinctive colors so in fact, finding out the color of the pixel is feasible in this case: we just need to sum up all these colors and divide the result by 256. But if the grid was infinitely large, this solution wouldn't work. If we want to find an approximation to this problem, all we need to do is sample say the image in 8 different locations (8 is just an example here. It represents the sample size N and its value can be anything you like), read the color of the grid at these locations, sum up these 8 colors and divide the result by 8. You can see this idea illustrated in Figure 3.

As you can see from Figure 3, the resulting approximation is close to the average color but a difference is visible. This is the pitfall of Monte Carlo methods, they just give us approximations. Another pitfall of the method is that you will get a different result each time you compute a new approximation. This is due to the random nature of the method (the location of the 8 samples changes each time we compute an approximation). For example, the following image shows the result of a series of 16 approximations of the same grid of color using 8 samples.

The good news though, is that you can reduce this error by increasing the number of samples. The bad news is that to minimize the error by 2, you need twice as many samples. This is the reason why Monte Carlo methods have the reputation to be slow. A more exact way of saying this is to say that their rate of convergence (how quickly they converge to the right result as the number of samples increases) is pretty low. This will be studied in detail in this lesson and the following one. The following series of images, show another run of 16 approximations with respectively 8, 16, 32, 64, 128, and 256 samples respectively.

As expected, the difference between each consecutive approximation is reduced as the number of samples increases. This difference in rendering is what you know as noise in your renders (assuming you are using a ray tracer). It is caused by the difference between what the actual solution should be and your approximation. Technically the correct name is variance (and probability and statistics have very much to do with the study of variance). You usually get more noise for a lower number of samples, or to say it differently by increasing the number of samples, you can reduce the noise (or the variance). However, note that the amount of variation you get from one approximation to another (assuming the same number of samples is used) also depends on how much variation there is between the colors from the grid. In the following example, we can see that there is far more color and brightness variation between the colors of the grid than in the previous example. While differences between successive approximations were barely visible in the previous case with 256 samples, with this grid and the same number of samples, differences are more clearly visible.

When does this happen? When you see through a pixel many objects or see just one or few objects with intricate surface details. Generally, though, you want to avoid situations where the visual complexity of what you see through a pixel is very large because the more details the more samples you need to reduce the noise. This idea also relates to the concept of aliasing and the concept of importance sampling. Here is the code we used to generate these results:
#include <fstream>
#include <cstdlib>
#include <cstdio>
int main(int argc, char **argv)
{
std::ifstream ifs;
ifs.open("./tex.pbm");
std::string header;
uint32_t w, h, l;
ifs >> header;
ifs >> w >> h >> l;
ifs.ignore();
unsigned char *pixels = new unsigned char[w * h * 3];
ifs.read((char*)pixels, w * h * 3);
// sample
int nsamples = 8;
srand48(13);
float avgr = 0, avgg = 0, avgb = 0;
float sumr = 0, sumg = 0, sumb = 0;
for (int n = 0; n < nsamples; ++ n) {
float x = drand48() * w;
float y = drand48() * h;
int i = ((int)(y) * w + (int)(x)) * 3;
sumr += pixels[i];
sumg += pixels[i + 1];
sumb += pixels[i + 2];
}
sumr /= nsamples;
sumg /= nsamples;
sumb /= nsamples;
for (int y = 0; y < h; ++y) {
for (int x = 0; x < w; ++x) {
int i = (y * w + x) * 3;
avgr += pixels[i];
avgg += pixels[i + 1];
avgb += pixels[i + 2];
}
}
avgr /= w * h;
avgg /= w * h;
avgb /= w * h;
printf("Average %0.2f %0.2f %0.2f, Approximation %0.2f %0.2f %0.2f\n", avgr, avgg, avgb, sumr, sumg, sumb);
delete [] pixels;
return 0;
}
Because we use ray tracing to evaluate the sample of this Monte Carlo integration, the method is called Monte Carlo ray tracing (it also called Stochastic Ray Tracing - The term stochastic is synonymous of random).
Three seminal papers introduced the method: The Rendering Equation (Kajiya 1986), Stochastic Sampling in Computer Graphics (Cook 1986) and Distributed Ray-Tracing (Robert L. Cook, Thomas Porter, Loren Carpenter 1984).
Let's now talk about the terms biased and unbiased. In statistics, the rule by which we compute the approximation of E(X) is called an estimator. The equation:
$$Approximation(E(X)) = { 1 \over N } \sum_{n=1}^N x_n,$$is an example of an estimator (in fact, it is a simplified version of what's known as a Monte Carlo estimator and we call it a basic estimator. You can find the complete equation and a complete definition of a Monte Carlo estimator in the next lesson). An estimator is said to be unbiased if its result gets closer to the expectation as the sample size N increases. We can demonstrate that this approximation converges to the actual result as N approaches infinity (check the chapter sampling distribution). Another way of expressing this is to say that the difference between the approximation and the expected value converges to 0 as N approaches infinity which we can write as:
$$Approximation(E(X)) - E(X) = 0 \text { as N approaches } \infty.$$This is the case with the Monte Carlo estimator. To summarize, the Monte Carlo estimator is unbiased. But when the difference between the result of the estimator and the expectation is different than 0 (as N approaches infinity) then this estimator is said to be biased. This doesn't mean though that the estimator doesn't converge to a certain value as N approaches infinity (when they do they are said to be consistent), only that this value is different than the expectation. At first glance, unbiased estimators look better than biased estimators. Indeed why do we need or would use estimators which results are different than the expectation? Because some of these estimators have interesting properties. If the bias is small enough and the estimator converges faster than unbiased estimators, for instance, this can be considered an interesting property. The result of these biased estimators may also have less variance than the results of unbiased estimators for the same number of samples N. In other words, if you compute the approximation a certain number of times with a biased estimator, you might see less of a variation from one approximation to the next, compared to what you get with an unbiased estimator (for the same number of samples used). This is also potentially an interesting quality. To summarize, you can either have a biased or unbiased Monte Carlo ray tracer. A biased MC ray tracer is likely to be less noisy for the same amount of sample used (or faster) compared to an unbiased MC ray tracer, however by using a biased estimator you will introduce some small error (the bias) compared to the "true" result. Generally, this bias is small though (otherwise the estimator wouldn't be of any good), and is not noticeable if you don't know that it is there.

We can extend the concept of Monte Carlo ray tracing further. As mentioned in the lesson Introduction to Shading, computing the color at the intersection point P of a primary or camera ray with the surface of an object requires integrating the amount of light arriving at P in the hemisphere of directions oriented about the normal at this point. If you haven't guessed yet, this is another integral, which very crudely we can write as:
$$L_P = \int_\Omega L_\Omega.$$Remember from the lesson on shading, that \(\Omega\) denotes the hemisphere. As usual, though, this involves integrating some quantity over a continuous area, to which there's no analytical solution. Thus, here again, we can use a Monte Carlo integration method. This idea is to "sample" the hemisphere by creating on its surface random samples and shooting rays in the scene from P through these samples, to get an approximation of how much light arrives at P (Figure 4). In other words, we cast random rays from the visible point P and average their result.
$$L_P \approx { 1 \over N } \sum_{n=1}^N L_n.$$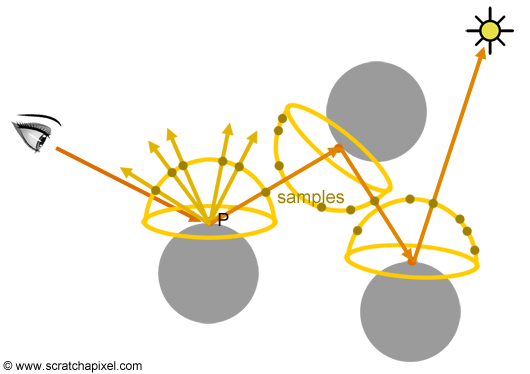
Again, this is how a Monte Carlo ray tracer typically works. Note that when we cast a ray from P into the scene to find out how much light comes from that direction, if we intersect another object along this ray, we use the same method to approximate the amount of light returned by this object. The procedure is recursive. Because we follow the path of rays, this algorithm is also sometimes called path tracing. You can see it illustrated in Figure 5.
This idea can also be expressed with the following pseudocode.
Vec3f monteCarloIntegration(P, N)
{
Vec3f lightAtP = 0;
int nsamples = 8;
for (int n = 0; n < nsamples; ++n) {
Ray sampleRay = sampleRayAboveHemisphere(P, N);
Vec3f Phit;
Vec3f Nhit;
if (traceRay(sampleRay, Phit, Nhit)) {
lightAtP += monteCarloIntegration(Phit, Nhit);
}
}
lightAtP /= nsamples;
return lightAtP;
}
void render()
{
Ray r;
computeCameraRayDir(r, ...);
Vec3f Phit;
Vec3f Nhit;
if (traceRay(r, Phit, Nhit)) {
Vec3f lightAtP = monteCarloIntegration(Phit, Nhit);
...
}
}
We will study this algorithm in detail in the lesson on path tracing.
Obviously, all that is a very quick and approximate (so to speak) introduction to Monte Carlo ray tracing. To get more accurate and complete information we strongly advise you to read the rest of this lesson, and the following one.
To conclude though, let's say that Monte Carlo methods are numerical techniques relying on random sampling to approximate results, notably the results of integrals. These integrals can sometimes be resolved using other techniques (if you are interested, you can search for examples for Las Vegas algorithms), however, we will show in the next lessons that they have properties compared to other solutions which are making them more useful (especially to solve the sort of integrals we have to deal with in computer graphics).
Monte Carlo is central to the field of rendering. It is connected to many very important other topics such as sampling, importance sampling, and light transport algorithms, and is also used in many other important rendering techniques (especially in shading).
What's Next?
To conclude this chapter, you can watch this fun video which is an extract from a BBC documentary. It shows the power of finding approximations to problems by averaging random numbers. The rest of this lesson will cover the basics of statistics and probability theory. It covers important notions such as the concept of PDF and CDF and the inverse method which we will extensively use in the next lessons.