Expected Value
Reading time: 25 mins.Expected Value
The concept of average or arithmetic mean is simple. If you have a group of people for instance and you want to measure the average height of the people from that group, you add up the height of every single person in that group and then divide the resulting number by the group size. Similarly, if you want to compute any other average value, such as the average of a group of \(n\) real values, you just sum up all the values and divide this sum by \(n\). The average value of the following set of 3 numbers {0, 1, 2} is (0+1+ 2)/3=1\. Simple.
If we get back to our 10 cards example we know that the sample space of this experiment (at least if we only consider the elementary events) is \(S = \{0,1,2\}\). If you don't know what the distribution of cards in the box is, you might be tempted to say that the average value of this experiment is the sum of the possible outcome values divided by the number of outcomes. In our example, this would be (0+1+2)/3=1. However, this answer is incorrect. Why? Because some of the numbers in the box appear more often than others and consequently because they have more "weight" in the computation of the mean, they do tend to attract the mean towards their value. Let's give an example. Imagine you have 4 cards labeled 0, 1, 2, and 2\. Now because the number 2 appears twice in this distribution, the mean of these 4 numbers will be pushed towards number 2: (0+1+2+2)/4=1.25\. Let's see what happens if we now have the following distribution: 0, 0, 1, 2\. The mean of these 4 numbers is: (0+0+1+2)/4=0.75\. Because the number 0 appears more often than the other numbers the mean is now pushed towards 0\. The resulting mean of the card's number in the box is the sum of each number multiplied by its weight. And how can we get these weights exactly? They can be computed by dividing the number of cards having a particular number by the total number of cards in the box, and if you haven't guessed yet, these are just the outcomes' probabilities. This can easily be verified with our 4 cards example:
$$ \begin{array}{l} mean &=& \dfrac{(0+1+2+2)}{4} \\ &=&0 * \dfrac{1}{4} + 1 * \dfrac{1}{4} + 2 * \dfrac{1}{4} + 2 * \dfrac{1}{4} \\ &=&0 * \dfrac{1}{4} + 1 * \dfrac{1}{4} + 2 * \dfrac{2}{4}.\\ \end{array} $$ $$S = \{0,1,2\}, \; p = \{ \dfrac{1}{4}, \dfrac{1}{4}, \dfrac{2}{4}\}.$$To conclude the correct answer for the mean of the card population can be computed by multiplying each number from the sample space by their probability: 0*2/10+1*5/0+2*3/10=1.1. However in statistics, to differentiate the first method which is a standard arithmetic mean (add up all the numbers and divide by the total number of cards), from the second method in which the same value is obtained by using probabilities instead, the result of the second method is called the expected value.
Again, note that the mean and the expected value are equal however the mean is a simple average of numbers not weighted by anything, while the expected value is a sum of numbers weighted by their probability. We can write:
$EV = \sum_{i=1}^N p_i x_i.$
Where EV stands for expected value, and \(p_i\) is the probability associated with outcome \(x_i\).
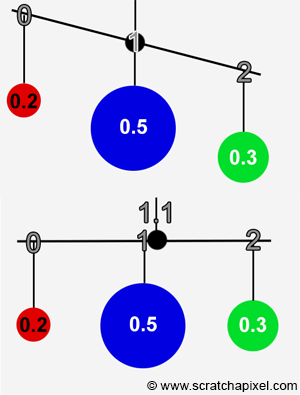
Computing this number is very similar to computing the center of gravity or pivot point if you prefer a mobile). If some objects are hung on a solid bar by a string and equally spread out, then the pivot of the ensemble is not in the middle of the bar (as shown below) but where the mobile reaches equilibrium which is the point on the bar where there is as much weight on the left then there is to the right (right in the image below. See how the pivot point moved slightly to the right). The mean of a population parameter can be seen as the same thing, where objects hung to the bar are the possible outcomes of the experiment and the weight of the objects are the probabilities associated with these outcomes.
Let's now formalize this concept. The mean of a population parameter is denoted with the greek letter \({\mu}\) (read "mu"). In our card example, you can compute this value in two ways. You can either add up all the numbers on the cards of all the cards and divide the resulting number by the total number of cards, or if you know the card's probability distribution (let's say we do have this information) then you can use the method described above: you multiply each outcome by its probability and add up the numbers. Let's write these two solutions and check they give the same result:
$$ \begin{array}{l} \mu &=&\dfrac{(0+0+1+1+1+1+1+2+2+2)}{10}=1.1,\\ EV&=&0 * 0.2 + 1 * 0.5 + 2 * 0.3=1.1. \end{array} $$As a practical example, let's compute the expected value of a die roll. We know we have 6 possible outcomes, 1, 2, 3, 4, 5, and 6 and that each outcome has probability \(1 \over 6\) thus:
$$EV = \dfrac{1}{6} (1+2+3+4+5+6) = 3.5.$$The reason why we made a gentle introduction to the idea that the expected value (which is equal to the population mean) of an experiment whose outcomes and probabilities are known can be computed by adding up the outcome values multiplied by their probabilities (and we hope to have convinced you this works through a couple of examples), is to help you get a better intuition of what we are going to talk about next which is maybe slightly more abstract. As we just mentioned, in a couple of examples that we used so far, the probability distribution and the outcomes of the experiments were known. But this is probably more often the exception than the rule especially when you work in the field of statistics. Example: if you knew ahead of time, the number of votes (the probabilities) given to each candidate (the possible outcomes) of an election let's say, then, of course, statistical studies (polls) would have no essence ratio. In the vast majority of cases, these variables are not known (sometimes the outcomes are known such as in the case of an election but they don't have to). This brings up the question: what do we do then?

If in your head, you answered "we use sampling" then you are on the right track. But we prefer to explain the idea from the random variable point of view. If you need to measure the property or population parameter but you know nothing about that population nor the possible range of outcomes for the parameter of interest, you are left with only one option: going out on the street and asking! Or if you are a bit more techie, you can use the white pages to pick random phone numbers of people living all across the country (of course the way you select phone numbers has to be truly "random" in other words impartial). You call these numbers and if you get someone on the line, assuming this person fits your selection criteria (he or she is an adult living in the Bahamas and not a child or a tourist), then ask for that person's height. Congratulations, you transformed yourself into a random variable. Let's assume then that as the person conducting this statistical study, you are the random variable that tries to measure a population's parameter which in our case is the adult population's height living in the Bahamas. Why are you random? You are random because each time you call to get the height of a person you take on a different value, for example, let's say 168 cm on the first call, 175 on the second, 167 on the third, etc. You keep changing. However your job as a random variable is to measure the average height of the adult population living in the Bahamas, so as you collect data and compute an average height from this collected data, something interesting starts to happen. At the beginning you take the average of your first two observations (168 and 175 divided by 2 = 171.5), then after three phone calls, the mean of the three first observations (168 and 175 and 167 divided by 3 = 170), etc. and you keep doing this as you collect new observations. What's interesting about the process is that each intermediate result is random (which is normal since each observation is a random number). For example, the mean of the first two observations is 171.5, the mean of the first three observations is 170, etc. thus each time we add a new observation and compute the mean of our random variable, using all the observations collected so far, the value of the mean changes. However what you will eventually observe, is that at some point, you will have so many observations, that adding one more observation to the computation of the mean is going to have less and less of an effect on the resulting value. Another way of looking at it is to say that the mean of the random variables converges to a singular value as the sample size increases, and if you haven't guessed yet, this value is the same as the expected value (and if you haven't guessed, we will explain it soon). This is generally easy to intuitively understand. If you have a thousand people whose height is between say 165 and 175 cm (and you have an average height of 170 cm so far) then having one individual whose height is very different from most people's height in your sample, is unlikely to have a great impact on the overall average height of that sample. You can see this as a dilution process. Adding a drop of milk to one liter of pure water is unlikely to make the water look cloudy.
This is a very long explanation for something that may seem obvious to you, but what we just described, plays an important role in justifying why from a mathematical point of view, statistics and the Monte Carlo method work. Let's take a practical example. Let's take a simple experiment such as rolling a die, and compute the mean of the results as we repeat the experiment over and over. We can simulate this with a simple C++ program printing out the mean of our random variable each time we add a new observation (in this program, we use a random number generator with a uniform distribution to draw random numbers between 1 and 6 but don't worry about this for now. We will just assume that this process is the same as throwing a die by hand). Because we can't run the program forever, we will stop after 1000 trials:
#include <random>
#include <cstdlib>
#include <cstdio>
int main(int argc, char **argv)
{
std::mt19937 rng;
rng.seed(2013);
std::uniform_int_distribution<uint32_t> die(1,6);
int sum = 0;
for (int n = 1; n <= 1000; N++) { //number of trials = n
int rnd = die(rng); //result of our random variable X
sum += rnd; //update sum
printf("%d %f\n", n, float(sum) / n); //print out sample mean
}
return 0;
}
If you plot the result of this program (graph the mean with respect to the number of trials used to calculate it), you can see that as the number of trials increases, the average of the value converges towards 3.5 (which we know is the expected value of the six-sided die).

Because everything in statistics has a name (and a precise meaning) the mean of a collection of observations produced by a random variable \(X\), is called a sample mean (remember that a collection of observations is called a sample or a statistics). The sample mean is generally denoted \({\bar X}\) which you can read as "X bar", and mathematically we can express it as:
$$\bar X_n = \dfrac{1}{n} (X_1 + X_2 + ... + X_n).$$Where \(X_1, X_2\), ... is a sequence of random variables which have the property to be independent and identically distributed (or i.i.d).
Question: "the X's in the sample mean definition correspond to observations. In the introduction on random variables, you mentioned that to distinguish observations from random variables which are denoted with upper case letters, you should use lower case letters for observations?" This is often a source of confusion indeed. We chose this notation because it is generally written that way in textbooks and there is a reason for this which are not yet ready explained. However, we can say this: random variables are functions from the sample space to \(\mathbb{R}\). \(\mathbb{R}\) denotes what we call in mathematics the real number space. Because of this, in mathematical jargon, we say that random variables (which are functions) can be manipulated algebraically pointwise. However, this is not so important. If you interpret a random variable as a function of some outcome \(\omega\) (where \(\omega\) can be any outcome from the sample space S) and observation as a result of this function, then you can write something like that \(x = X(\omega)\). And rather than writing \(\bar X = {1 \over n } (x_1+x_2+...+x_n)\) you can as well write \(\bar X = {1 \over n} (X_1(\omega)+X_2(\omega) + ... + X_n(\omega)\). Another way of saying this is that you can see these \(X_1, X_2\), ... as instances of the random variable \(X\).
To explain what i.i.d means, we will take an example. Let's consider the case of an unfair coin flip (i.e. the probability of getting either tails or heads is not the same. We can also speak of a loaded coin). Imagine that this coin lands on heads with probability \(2/3\), and tails with probability \(1/3\). If we flip the coin twice, the outcome of the first coin flip will not change the outcome of the second. Thus the results are independent (we have already explained this concept in chapter 3). Note also that when the coin was flipped the first time, the probability of either getting heads or tail was \(2/3\), and \(1/3\) respectively. Note also that when the coin is flipped the second time, the probability of actually getting either heads or tails is still \(2/3\), and \(1/3\). In other words, the probability that you get either heads or tails after the first flip doesn't change. What makes the results identically distributed, is the consistency in the probability associated with each possible outcome, as the experiment is repeated again and again. In conclusion, even though the coin was loaded, the sequence of obtained random variables is i.i.d. In short, I.i.d random variables are independent of each other and have the same probability distribution.
In summary, our C++ program shows that as the sample size increases, the sample mean converges to the expected value:
$\bar X_n \approx EV.$
Where the symbol \(\approx\) means "approximation" (but it would be better in our context to take the habit of using the word estimation instead and we will soon explain why). The idea that the sample mean converges in value and probability to the expected value as the sample size increases, is expressed in a theorem from probability theory known as the Law of Large Numbers (or LLN). They are a few possible approaches to explaining the theorem; one way is to consider that as the number of trials becomes large, the relative frequency of each outcome from the experiment tends to approach the probability of that outcome. If we roll a die 6000 times, about 1000 of these trials should be 1s (it might not be exactly 1000 but should be very close if it isn't), about 1000 should be 2s, etc.
Interestingly enough, note that the higher the number of trials, the smaller the probability of getting exactly the number of trials divided by 6 (assuming the number of trials is a multiple of 6). You can also look at the problem with a simpler experiment. If you toss a coin 10 times, what is the probability that you get 5 heads? This can be computed analytically using the binomial distribution:
$$ \left( \begin{array}{cr} 10 \\ 5 \end{array} \right) \left( { 1 \over 2 }\right)^5 \left(1 - {1\over 2}\right)^5 = 0.2461. $$But if you now consider 100 trials, the probability becomes:
$$ \left( \begin{array}{cr} 100 \\ 50 \end{array} \right) \left( { 1 \over 2 }\right)^{50} \left(1 - {1\over 2}\right)^{50} = 0.0796. $$As you can see, the higher the number of trials, the smaller the probability of getting exactly N/2 number of heads (where N is the number of trials). This is an important distinction to make when trying to understand the concept of the Law of Large Numbers which is that it guarantees that the proportion of heads gets closer to 1/2 as \(n\) increases, however as mentioned before, interestingly the probability to get exactly N/2 heads to get smaller. You can mathematically prove this. Let's for example calculate the probability that we can any number of heads between 40 and 60 for 100 trials (this is just the sum of the probabilities to get exactly 40, 41, ... 60 heads):
$$ Pr(40 \leq X \leq 60) = \sum_{i=40}^{60} \left( \begin{array}{cr} 100 \\ i \end{array} \right) \left( \dfrac{1}{2} \right)^i \left( 1 - \dfrac{1}{2} \right)^{100 -i} = 0.9648. $$However, if we compute the probability of getting any number of heads in the interval [4,6] for 10 trials, then we get:
$$ Pr(4 \leq X \leq 6) = \sum_{i=4}^{6} \left( \begin{array}{cr} 10 \\ i \end{array} \right) \left( \dfrac{1}{2} \right)^i \left( 1 - \dfrac{1}{2} \right)^{10 -i} = 0.6563. $$The probability of getting close to 1/2 increases as the number of trials increases.
As you can see, the number of trials corresponding to each number divided by the total number of trials approaches the probability of each outcome. In the die example, we know that the probability is \(1/6\) but as you can see, when we don't know what that probability is, the sampling approach can be used instead to estimate it. And it works! Another way of explaining the theorem is that it guarantees stable long-term results for the averages of random variables. In other words, as we keep increasing the number of trials, the theorem tells us that the average of a discrete random variable tends to approach a limit which is the random variable's expected value (see the grey box above for more details on this):
$$\bar X_n \xrightarrow{p} E[X] = \mu \text{ as } n \rightarrow \infty.$$The superscript p over the right arrow, means "converges in probability". You can also define this property as:
In words, it means that the probability that the difference between the sample mean and the population mean is smaller than a very very small value (here denoted by the greek symbol epsilon \(\epsilon\)) is 1 as \(n\) approaches infinity. We generally speak of convergence in probability. In conclusion, you should remember that the sample mean \({ \bar X }\) of a random sample always converges in probability to the population mean \({\mu}\) of the population from which the random sample was taken.
What the expected value of a random variable means is not often made very clear. When you write \(E[X_1]\) for instance where \(X_1\) is a random variable, then what it refers to, is very simple. Of course, \(X_1\) on its own, is likely to take on any value but its expected value\(E[X_1]\) is fixed. And this fixed value is the same for all random variables \(X_1, X_2, ... X_n\): \(E[X_1] = E[X_2]=...=E[X_n]\). This is something that you can see as a property they share and this happens because all these random variables share the same probability distribution and are thus necessary to have the same expected value. And by definition, this expected value of a random variable is also equal to the population mean (see again the beginning of this chapter). Then note that:
$E[X_1]=E[X_2]=...=E[X_n]=\mu.$
They are equal but then keep in mind that they are computed differently: the mean is a simple average of numbers, while the expected value of a random variable is computed by adding up the outcomes weighted by their probability (and thus the expected value depends on the probability distribution of the outcomes). In the Wikipedia article on the Law of Large Numbers, the symbol \(\mu\) is used in place of \(E[X]\), which is confusing because ideally, it is best to keep the concept of the population mean and expected value of a random variable separate, even if their values are equal.
IMPORTANT: there are many concepts in probability and statistics you need to know about, but we believe this concept is pivotal for understanding everything else. Be sure it is clear in your mind that by definition the expected value of a random value \(X\) is equal to the population mean. It will be used extensively in the next chapters.
At this point, it's time to maybe step back a bit and summarize the things we learned (and give a more formal definition of what an expected value is). First, we hope to have made it quite clear now that the expected value of \(X\) depends only on the distribution of \(X\). That has hopefully been fully explained above. Thus two random variables which have the same distribution have the same expected value. If you sample the population of The Bahamas and a friend of yours does the same thing at the same time, you are two different variables however you will both come up with the same expected value for the population's height. The expected value has also several synonymous: it is also called mean or expectation. Avoid using mean though as it can easily be confused with the population mean. Generally, you can interpret the expected value of a random variable \(E[X]\) as a summary of its distribution. If the probability distribution is thought of as a distribution of objects (the outcomes) of a certain weight (the outcomes' probability) along a line, then the expected value can be seen as the center of mass. Finally of course, if we know the distribution of the random variable we can compute the expected value directly (rather than using samples and relying on the Law of Large Numbers):
$$E[X] = \sum_{i=1} p_i x_i \rightarrow = \sum_{\omega \in S} X(\omega) p(\omega).$$Where \(p(\omega)\) is some function returning the probability of the outcome \(\omega\). As mentioned several times, the expected value is the sum of the outcomes \(x_i\) weighted by their respective probability \(p_i\). And finally, the population mean and the expected value are equal: \(\mu = E[X]\).
Properties of Expectations
Expectations have properties that are important especially to prove some of the techniques we are going to introduce next.
Property 1: first, if you consider \(Y = aX + b\) (the random variable Y is equal to the random variable X weighted by some factor plus a constant) then:
$$E[Y] = aE[X] + b.$$It is not very hard to understand intuitively. If you consider an experiment in which the numbers on a die are all multiplied by 10 for instance, then the expected value of this random variable is 35 (10 times 3.5, the expected value of a basic six-sided die). However, if you want proof you can write:
$$ \begin{array}{l} E[aX] &=& \sum_i a x_i P(X = x_i) \\ &=&a \sum_i x_i P(X = x_i)\\ &=&aE[X]. \end{array} $$If \(X = c\) where \(x\) is a constant (in other words, the probability that can take on the value \(c\) is 1), then \(E[X] = c\). Here again, this is not very hard to understand. If a die had the same number on all its faces, then its expected value is that number.

Property 2: the expected value of a sum of random variables is equal to the sum of the expected value of each random variable making up that sum (the expected value of a sum is the sum of the expected values):
$$E[X_1 + ... X_n] = E[X_1] + ... + E[X_n].$$If we flip a coin and let X have the value 1 if the coin comes up heads and 0 if the coin comes up tails. Then, if we roll a die and let Y denote the face that comes up. What is the probability that both X and Y (which you can write X + Y) occur at the same time? In chapter 3 (on probability properties), we have explained that the answer to this question is the product of the individual probability of X and Y to occur, which is known as the multiplication rule. In other words, the joint probability to get X = 1 (where X is defined to be 1 if the toss comes up heads and 0 otherwise) is the random variable and Y = 2 (where Y is the outcome of a die roll) is equal to the product of each outcome to occur, that is:
$$Pr(X = 1, Y = 2) = {1 \over 2} \times {1 \over 6} = {1 \over 12}.$$In probability, we can express the combination of two random variables as a third one Z = (X,Y) where Z is called a joint random variable whose outcomes are ordered pairs of the form \((x, y)\), where \(0 \le x \le 1\) and \(1 \le y \le 6\) in the case of our example. In other words, we can say the probability of getting heads and 2, or to say it differently the probability of getting outcome 3 (as a result of getting heads and 2) is the probability of getting heads multiplied by the probability of getting 2 which you can write: Pr(X = 1, Y = 2). With this tool in hand we can write (remember that an expected value is the sum of all the outcomes of an experiment multiplied by their respective probabilities):
$$ \begin{array}{l} E[X + Y] &=&\sum_i \sum_j (x_i + y_j) Pr(X = x_i, Y = y_i) \\ & = & \sum_i \sum_j x_i Pr(X = x_i, Y = y_i) + \sum_i \sum_j y_j Pr(X = x_i, Y = y_i) \\ & = & \sum_i x_i Pr(X = x_i) + \sum_j y_j Pr(Y = y_j) \\ &=&E[X] + E[Y].\end{array} $$Keep in mind that the sum of the probability for a given experiment is 1 which is why we can write (the probabilities for Y sum to 1 thus we can remove this sum from the equation):
$$\sum_j Pr(X = x_i, Y = y_j) = Pr(X = x_i),$$and (the probability for X sum to 1 thus we can remove this sum from the equation:
$$\sum_i Pr(X = x_i, Y = y_j) = Pr(Y = y_j).$$If you still have a doubt, you can compute the result for yourself using the coin/die example. We know the individual expected values of the coin and die experiment are 0.5 and 3.5 respectively thus the sum should be 4\. Let's check (we have 12 possible outcomes as illustrated in the adjacent figure with probability \(1\over 12\)):
$$ \begin{array}{l} E[X + Y] &=& (0+1)\dfrac{1}{12} + (0+2)\dfrac{1}{12} + (0+3)\dfrac{1}{12} + \\ && (0+4)\dfrac{1}{12} + (0+5)\dfrac{1}{12} + (0+6) \dfrac{1}{12} + \\ && (1+1)\dfrac{1}{12} + (1+2) \dfrac{1}{12} + (1+3) \dfrac{1}{12} + \\ && (1+4) \dfrac{1}{12} + (1+5) \dfrac{1}{12} + (1+6) \dfrac{1}{12} \\ &=& (1 + 2 + 3 + 4 + 5 + 6) \dfrac{1}{12} + (2 + 3 + 4 + 5 + 6 + 7) \dfrac{1}{12} \\ &=& \dfrac{21}{12} + \dfrac{ 27}{12} = 4 = 0.5 + 3.5. \end{array} $$A similar theorem exists for the product of independent random variables but we won't be using it and we can ignore it for now. Some other properties exist but they are not used in rendering.
Summary of Terms
It is important at this point of the lesson, that you make a clear distinction between:
-
The sample mean \(\bar X\) (our estimate).
-
The population mean \(\mu\) (the exact mean of the population parameter we try to estimate).
-
The expected value \(EV\) or \(E[X]\) (which is also the exact mean of the population we try to estimate but computed from adding up the outcome of the experiment weighted by their probability).
Be very careful when you read other documents on statistics (including articles on Wikipedia) because not all sources use the same conventions. The expected value and the term mean are synonymous. However, the mean is not to be confused with the population mean. Furthermore, even though it is generally accepted that the population mean is denoted with the symbol \(\mu\) this symbol is also sometimes used for the mean or the expected value (instead of E[X] or EV). There is nothing we can do about this situation. At least, in this lesson, we have tried to be consistent with our notation.